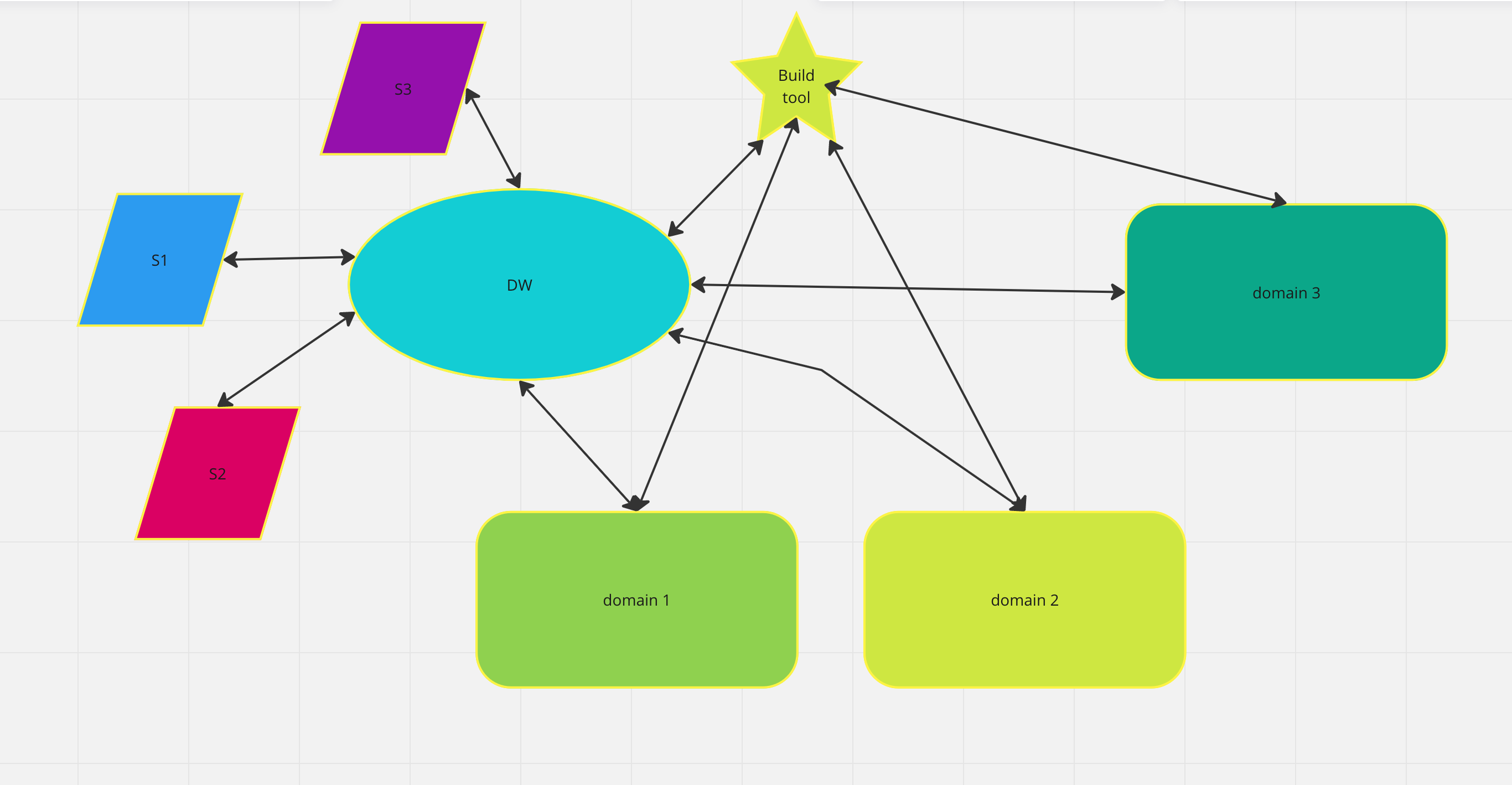
Perhaps you’ve heard of ELT and it’s older, usually grouchy and recalcitrant, cousin ETL. Both are acronyms representing the same stages of getting your data from somewhere to somewhere (Snowflake, Big Query, etc) else and doing valuable and important things with it. Both imply some repeated process to keep the somewhere else part up-to-date.
ELT, which stands for Extract, Load, and Transform, is a data integration process that is similar to ETL (Extract, Transform, Load) but with a different order of operations. In an ELT process, data is first extracted from source systems and loaded into a data warehouse or data lake. The transformation step then takes place within the data warehouse or data lake, where the data is transformed, cleaned, and enriched. ELT is the new hotness and what the modern tools are doing.
One advantage of ELT over ETL is that it allows for more flexibility in terms of data processing and analysis. With ELT, data can be processed and analyzed in real-time, allowing for faster insights and decision-making. ELT also allows for the use of modern data processing tools and technologies, such as Apache Spark and Hadoop which can handle large volumes of data and complex data processing tasks. DBT, Dataform and Coalesce.io are Transform tools that can speed up discovery, insight and development of such. They’re also built with support for modern and fast development practices as part of their mission – You want this, this is good for business.
However, ELT can also have its challenges. One major challenge is the increased complexity of the data processing and transformation steps within the data warehouse or data lake. This requires a higher level of technical expertise and can result in longer processing times and increased costs. But, there’s a caveat to that. ETL tools are usually monolithic, expensive, cumbersome to manage and require a lot of compute resources; think Oracle and Informatica. Monolithic is bad because it makes changes hard to make without affecting the whole thing. Further, these tools don’t play well with modern development practices. Enough about that.
Overall, ELT can be a powerful tool for data integration and analysis, but it’s important to carefully consider the specific needs and requirements of your organization before choosing an ELT approach. Additionally, it’s important to have a strong data architecture and a clear understanding of the data sources and transformation processes involved in order to successfully implement an ELT solution.
From here on, let’s focus on the Extract and Load part. Those are the first steps and sometimes the most cumbersome part of ELT projects. Cumbersome because many companies have custom applications and 3rd party platforms that are unique to their industry. You can’t always simply “get to the data”. However, in some cases, off the shelf tools work and it’s straight forward (inexpensive and quick). There are lot’s of tools and platforms for that. Often there’s a need to custom code stuff and combine that with the big cloud platforms.
Cloud platforms such as GCP, AWS, and Azure offer a range of services and tools for data extraction and loading. For example, AWS offers services such as AWS Glue, which is a fully managed extract, transform, and load (ETL) service that can automatically discover and extract data from various sources, transform the data using a variety of built-in transformations or custom transformations, and load the data into a data warehouse or data lake.
Similarly, GCP offers services such as Cloud Dataflow, which is a fully managed service for developing and executing data processing pipelines. Cloud Dataflow can be used for both batch and stream processing, and supports a variety of data sources and sinks, including Google Cloud Storage, BigQuery, and Cloud Pub/Sub.
In addition to these cloud platforms, there are also many third-party tools and platforms available for data extraction and loading. These tools range from simple file transfer tools to more complex ETL tools that offer advanced data transformation capabilities.
In some cases, custom coding may be necessary to handle unique data sources or to integrate with specific cloud platforms. For example, if you need to extract data from a proprietary database system, you may need to develop custom code to interface with that system. Similarly, if you want to load data into a specific cloud platform, such as BigQuery on GCP, you may need to develop custom code to interact with the BigQuery API. Don’t let that scare you off; Google makes this super easy.
Overall, there are many options available for data extraction and loading, and the choice of tools and platforms will depend on the specific needs and requirements of your organization. It’s important to carefully consider the capabilities and limitations of each tool and platform, and to have a clear understanding of your data sources and integration requirements before making a decision. Additionally, having the ability to develop custom code can be a valuable asset in order to handle unique or complex data integration scenarios – We can bring that, of course.
Having a consulting firm like Signal Scout that can provide customized solutions for each client’s unique needs and requirements is a valuable asset for companies looking to implement effective Extract and Load processes.
By carefully listening and considering the specific needs of each client, Signal Scout can help ensure that the Extract and Load architecture and implementation is optimized for their particular use case. This may involve leveraging different ETL tools and platforms, custom coding, or a combination of both.
In addition, by working with cloud platforms like GCP, AWS, and Azure, Signal Scout can help clients take advantage of the scalability, flexibility, and cost-effectiveness of cloud-based data storage and processing. This can be especially important for companies that need to handle large volumes of data, as traditional on-premise solutions may not be able to scale effectively or cost-efficiently.
Overall, having a consulting firm like Signal Scout that can provide customized solutions for Extract, Load and Transform processes can help companies optimize their data integration and processing workflows, which can in turn lead to better data-driven decision-making and improved business outcomes.